The Fun and Pain of Rebuilding My Auth Flow
Some pull requests are like that. You open them thinking youre just tightening a screw somewhere, and by the end you’ve rebuilt half the engine!
This was one of those moments. I only wanted one thing, I dint want to expose the static
files stored by an app to anyone who had access to a file path.
A colleague suggested adding a jwt_required decorator around all protected backend routes,
as done in the basic usage docs.
Thats it, no grand architecture work, no deep redesign. Just some basic auth flow. The plan was extremely straightforward:
- authenticate user with pw from a postgres database
- user exists and pw matches, issue an access token
- access token added to all requests from frontend thereon
- store the access token in the
sessionStorage
Yeah, because easy to implement, enough for a PoC.
Implemented a first version, iterated a few times with GH Copilot, it wants to help, asked for a code review – yeah sure, why not? 10 seconds in, we’re building new features with Copilot by the side (because thats how fast we ship with Copilot nowadays) for,
- access-token refresh
- run a periodic keepalive
Yeah sure, I thought, makes sense, lets do it. It’s a Friday evenning, lets update the docs, push it and discuss on Monday.
I was convinced this would be a short PR. The kind you merge the same evening and forget about – the thing you do with only some water, some chips and a few tokens. Speaking of tokens, I was also reaching my token limits (~95%) for GH copilot enterprise at the end of the month, as everyone does.
Simply put, it did not stay short. I had to bring in coffee, beer and more tokens! It carried over to the weeked, a weekedn that I wanted to spend on Mistral Worldwide Hacks.
What actually happened
The moment I touched the auth flow, I realized there is no such thing as a “small change” in authentication. Every decision changed something else: frontend behavior, backend guarantees, and on and on – hidden player was the browser (why is browser determinism not a thing?). Very quickly I ended up modifying almost everywhere and anywhere auth exists:
- frontend login/session bootstrap
- cookies or session or local storage?
- API wrapper behavior
- global keepalive logic
- refresh endpoint semantics
- token rotation strategy
- and a complete refresh-token revocation model in Postgres
At some point this stopped being a patch and became a redesign.
I initially treated refresh tokens as just a way to mint new access tokens. But that model breaks down immediately if old refresh tokens remain valid forever. Somebody else could hold that refresh token somewhen and ask for a new access token. Rotation alone becomes meaningless..
Once I accepted that, everything else had to be rethought properly.
1. Refresh will just happen in time
My first assumption was simple: the keepalive loop will refresh before expiry anyway. Yet I kept seeing 401s on something as basic as /api/health – it would go fine for 10 minutes and the lots turned red in a few minutes when I got up to get another coffee.
After staring at logs longer than I care to admit, I realized my sequence was wrong. I checked health first and refreshed second. If the token had already expired, the health call failed before refresh even ran – leaving the user with a pile of snackbar notificaitons. I just didnt know (yet) when that condition is met.
So the system behaved exactly as designed, just not exactly as intended! The fix was straightforward: refresh-first logic. Before any protected call, ensure token validity. Only then proceed.
If not valid, try to reissue the access token, with the HttpOnly reissue token.
2. Route-level keepalive was a bad idea
My first implementation tied the refresh interval to a specific route. It worked beautifully while sitting on that page. The moment navigation changed and user left elsewhere, the token checks stopped silently. Tokens expired, which had cascading effecst: sessionStorage cleared and user forced to logout. Its not that dangerous to speak, the user could get a new access token reissued if their refresh token were still valid. But that could never happen because of the point above and even if that was sorted, a new refresh token should also be issued (and the old one revoked) with every refresh request.
That meant refresh depended on where the user happened to be in the UI. Which is obviously fragile once you think about it. It also implied that if the tab “slept” (to save ram, thanks chrome), the refresh requests would go for a nap as well. This is why the refresh should happen in time.
The fix was to move keepalive to application scope. Once it lived at app level, everything came back to life.
Even with a perfect keepalive, race conditions still exist. A request can always slip in between refresh cycles and hit the backend with an expired token. That is unavoidable. Initially those requests would fail and surface as user-visible errors. The missing piece was request-time recovery. Inside the API wrapper I added a single controlled fallback:
- if a request returns 401 (and it is not an auth endpoint),
- attempt refresh once,
- retry the original request once.
That single change made expiry feel invisible to the user instead of disruptive.
3. Rotation without revocation is incomplete
I implemented refresh-token rotation and felt quite pleased with it. Each refresh returned a new refresh token. The old one was replaced client-side. Everything looked correct. Then came the uncomfortable question, again from Copilot’s code review: what if an old refresh token leaks?
If the server still accepts it, rotation alone does nothing. We end up with a world full of old refresh tokens that are still valid. I picture this in my head like so: a bank vault exploding and money rain everywhere, people picking it up and going in to buy PS5s. This is not a world that I would want to live in – so I continued late into the night, adding methods to:
- store refresh tokens with
jti - revoke-on-use rotation
- blocklist checks
- replay detection
In short all revoked and replaced refresh tokens were then written to Postgres for lineage and tracking. This meant more lines of code in dreaded-SQL.
The surprisingly fun part
Going into the Chrome Dev panel and tracking each request to the backend, its headers, responses (the green lights), response headers and just waiting for that cookie to be registered in the frontend was a painful exercise, but “fun” – as one should state on the internet.
I later realized that the cookie (with
request_tokenwas registered) but was never included in the request for one route! Simply because I had used a non-standardfetchfor that route withoutcredentials: "include"in the request header, even after spending hours writing a singleurlFetchInterfacefor all requests from frontend that would’ve done/was doing it by default. That route also turned out to beauth. I thought I had enough coffee. What else could go wrong?
The main concepts that I learned in this process are, but not limited to:
- short-lived access tokens
- refresh token in httpOnly cookie
- frontend recovery from expected expiry
- rejecting replayed refresh tokens
- explicit revocation state
Here is my mental model for future reference:
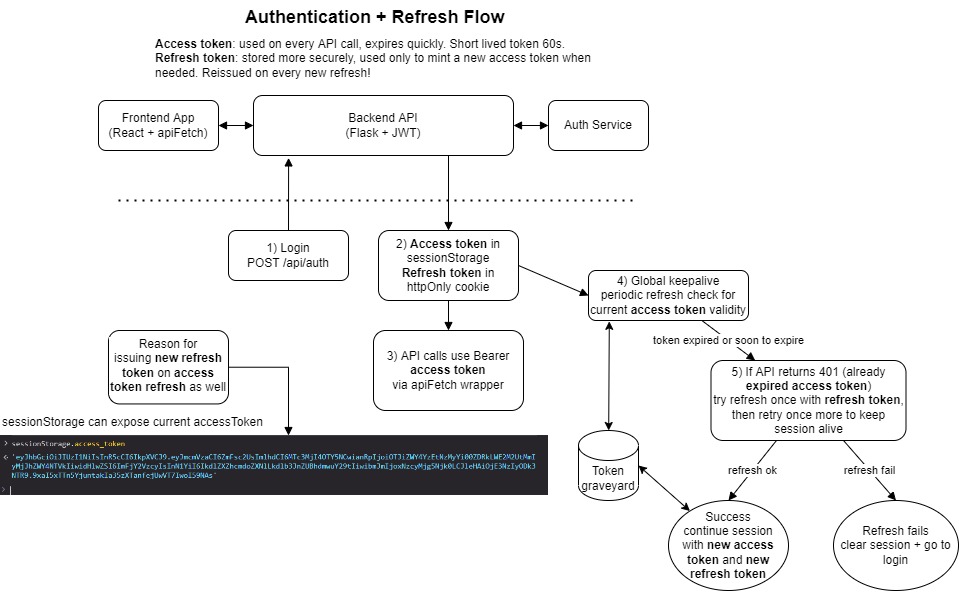
The dread that remains
All of that done and tested in a local docker/podman environemnt – I did try to match the dev environment as close as possible by isolating the environemnt and creating local CA certs to have https, CORS and browser cookies stability with localhost that follow SameSite and cross origin rules. The only fear is how much of that would now carry over to dev/prod.
I also question why was this even necessary if everything was working fine without this auth flow and if we have “nice” users who are anyway within a vnet and talking to an onprem only k8s deployment? Turns out web browsers arent our friends and they behave odd.
Only monday would tell. This PR took longer than expected.. hopefully I won’t have to touch auth again for at least.. a week?